
Without proper file management, having staff change over time and different technologies coming and going, it can be quite difficult to keep everything in order. What about if someone leaves – their institutional knowledge is lost. This could be catastrophic if they were the only one!
Our issues weren’t quite this bad, but over time our department and the wider organisation had bits and bobs everywhere – user guides, instructions, hand-overs. Some people would drop it in an email, others a message over Teams. Others organised a channel, some a OneNote, and others hosted a collection of PDFs on the CMS. Not only was it hard to find something if you needed it (if you even knew it existed!) but it was also difficult to keep it all updated, more so if you don’t have the access.
What we needed was a single point of truth.
⚪ Reinventing the wheel
Some things are just so complicated.
But why should a Wiki be? There was a beautifully long list of PHP Wiki solutions on GitHub (which I can’t seem to find now, but similar to this GitHub Wiki Topic list) that me and the Back-End Web Developer went through one-by-one, reading all of their README files and even downloading and installing a couple. But, even though some of them (DokuWiki, MediaWiki, BookStack, PhpWiki etc) are all fantastic, we just didn’t need the level of micromanagement that they offer.
What we needed, in essence our only requirement, was simplicity. Simplicity for the person creating pages with no coding knowledge required, and simplicity for users to find what they’re looking for.
💭 The thought process
What’s simpler than a single PHP template to run the entire Wiki, ey? Ah, yes. The simplicity did not extend to the actual code so much, but the logic is sound.
Initially, this logic was to take the URL, explode it into component parts in a repeating pattern and deliver the appropriate infinitely nested content. If, at any point there was no further segments, it would display the page if one existed or an error if there wasn’t one.
Time for a Paint-ented diagram to explain:
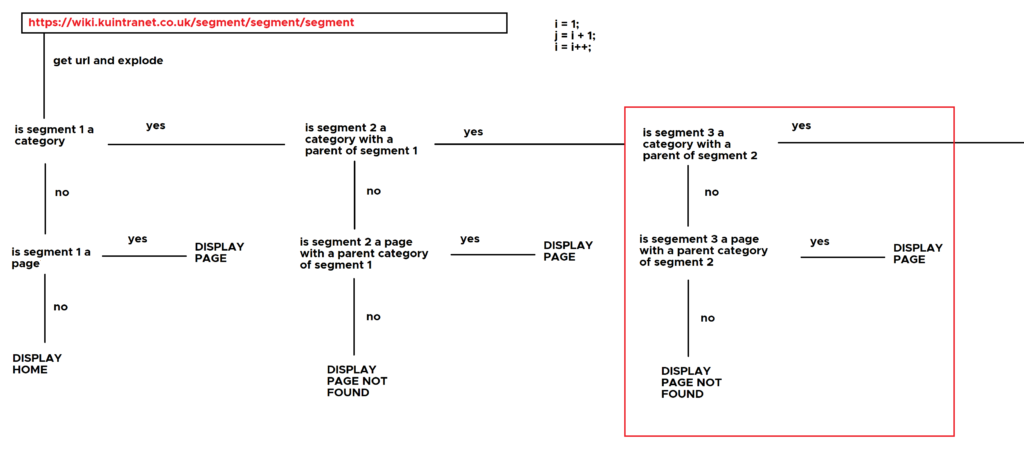
🧨 What the process ended up as
Why infinite nesting though? You’d never find what you’re looking for if something is in a tiny box, in a bigger box, in an even bigger box, in a truck, on a random highway! Instead, the idea of the Bookshelf was born.

Yes, that’s right, Bookshelves didn’t exist before now.
Instead of infinitely nesting, Books are separated into Chapters, and Chapters are a collection of Pages. The flowchart below (slightly abridged and Excalidraw, not Paint this time) follows the nested IF functions to display either the content, or an error if there is a segment but which does not have content.
By parsing the URL and exploding using /, an array is created which can be compared against the Book/Chapter/Page URL column in the database, depending on the level. And because this solution relies on the URL, direct links can be shared by users without a second thought.
👨💻 How does this look like in code?
Again abridged, quite heavily this time, the following code demonstrates the structure of the nested IF functions:
<?php
$url = parse_url($_SERVER['REQUEST_URI'], PHP_URL_PATH);
$segments = explode('/', $url);
if (!$segments[1]) {
// HOMEPAGE AND LIST BOOKS ON THIS BOOKSHELF
} else {
// SELECT * FROM BOOKS WHERE BOOK = $SEGMENT[1]
if ($resultBooks) {
if ($segments[2]) {
// SELECT * FROM CHAPTERS WHERE BOOK = $SEGMENT[1] AND CHAPTER = $SEGMENT[2]
if ($resultChapters) {
if ($segments[3]) {
// SELECT * FROM PAGES WHERE CHAPTER = $SEGMENT[2] AND PAGE = $SEGMENT[3]
if ($resultPages) {
// PAGE CONTENT
} else {
// NO PAGE WITH THIS TITLE IN THIS CHAPTER
}
} else {
// CHAPTER CONTENT AND LIST PAGES IN THIS CHAPTER
}
} else {
// NO CHAPTER WITH THIS TITLE IN THIS BOOK
}
} else {
// BOOK CONTENT AND LIST CHAPTERS IN THIS BOOK
}
} else {
// NO BOOK WITH THIS TITLE ON THIS BOOKSHELF
}
}
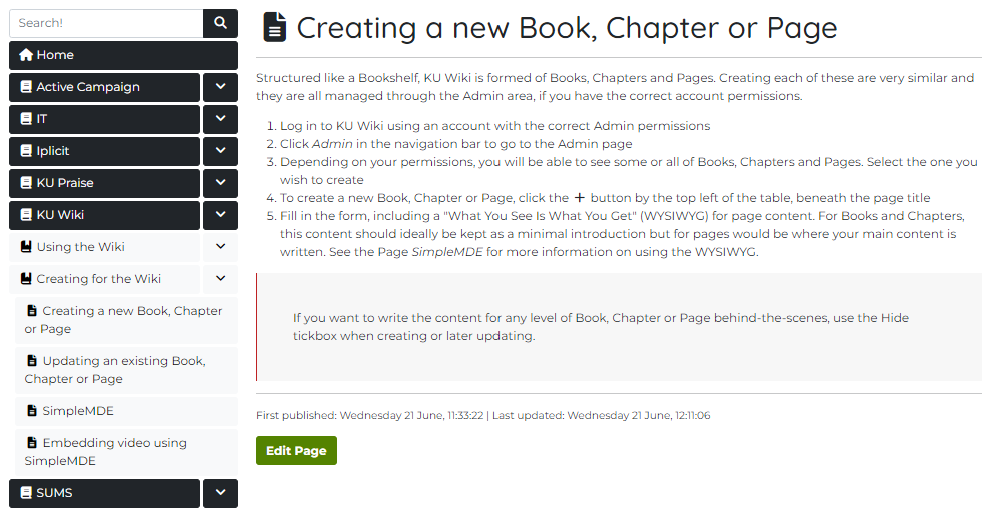
?>📑 What the Page level looks like
At the Page level, the final box on the flowchart, the segment-matching contents from the Pages table is shown. Stored creation and updated dates are formatted into a user-friendly arrangement and the stored Markdown content is run through the Parsedown library to format into HTML.
$pageId = $rowPages['pageId'];
$pageName = $rowPages['pageName'];
$pageURL = $rowPages['pageURL'];
$pagePublished = $rowPages['pagePublished'];
$pagePublishedFormatting = strtotime($pagePublished);
$pagePublishedFormatted = date("l j F, H:i:s", $pagePublishedFormatting);
$pageUpdated = $rowPages['pageUpdated'];
$pageUpdatedFormatting = strtotime($pageUpdated);
$pageUpdatedFormatted = date("l j F, H:i:s", $pageUpdatedFormatting);
$pageContent = $rowPages['pageContent'];
$pageParsedown = new parsedown();
$pageParsedownContent = $pageParsedown->text($pageContent);
echo '<h1><i class="fa-solid fa-file-lines fa-fw me-1" aria-hidden="true"></i>' . $pageName . '</h1>';
echo $pageParsedownContent;
echo '<p><small>First published: ' . $pagePublishedFormatted . ' | Last updated: ' . $pageUpdatedFormatted . '</small></p>';If the user has the granular permission to edit, a button appears at the bottom of the page direct to the admin page to update this specific page. The same applies for Chapter and Book layers too, but in addition to their own Markdown content a list of their children are shown too.
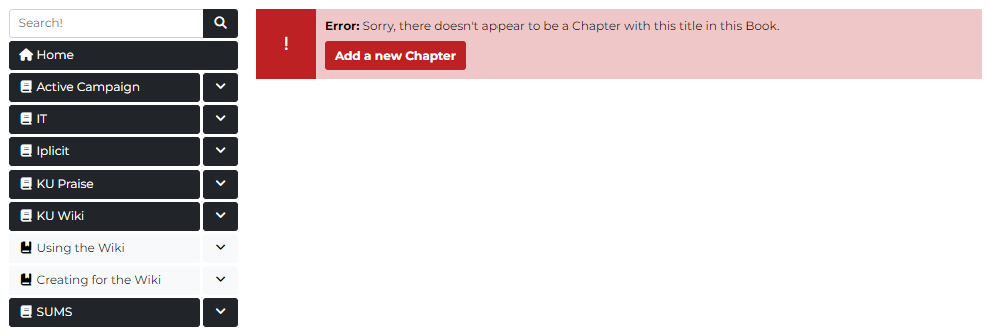
🚫 What about when the segment doesn’t exist?
If the segment returns no database matches then an error reading: “Sorry, there doesn’t appear to be a Page with this title in this Chapter.” is displayed. Plus, if the user has the granular permissions to create, a button appears directly taking the user to the admin creation area.
And, again, both of the above points apply to Chapter and Book layers too.
🔗 Resources
Here’s some links to the pages I used to help guide the creation of Shelf Wiki:
- GitHub Wiki Topic list
- Markdown Guide: Cheat Sheet
- Infinite Dynamic Multi-Level Nested Category with PHP and MySQL
- CodexWorld: How to get URI Segment in PHP
- Parsedown
This article was written retrospectively in November 2023, and is part of several blog posts breaking down the Shelf Wiki system, such as this article on how to Search. Coming soon will be articles on the Navigation and also the back-end areas, including looking at SimpleMDE and Parsedown.